Extract text from most types of images, word processing, spreadsheets, PDFs and other files.
Programmers and developers often get called upon to create applications to convert scanned images into editable documents. The original might simply be scanned text, a word processing document, spreadsheet, Adobe PDF, etc. The client will usually want these documents brought back to their original format. For this, there is only one solution, a document management system combined with Optical Character Recognition (OCR). And in order to this, one needs to use an OCR developer toolkit. Although such toolkits might cost several thousand dollars or more, the results are quite outstanding.
However, there are situations where the output of such processing will only be needed for text indexing and searching. This is usually so in the case say of litigation support. In such instances, powerful and expensive OCR engines are overkill. Quite inexpensive and relatively simple alternatives exist. In fact, these alternative may yield more accurate results. If formatted output into a native file type is not required, Microsoft’s indexing service is an excellent alternative.
Fortunately, Microsoft provides a programmatic interface to this service. The IFilter is a COM interface developed by Microsoft for its Indexing Service to extract text from files so the Indexing Service can create indexes for searching. If you installed the Indexing Service, then you should have filters for most of the common file types. The IFilter interface is used mainly in non-text files such as image files, Office documents, PDF etc. It can also be used on text files such as HTML and XML. Some versions of Windows come with IFilter implementations for Office files. There are also numerous free and commercial filters for other file types.
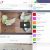
teXtracta allows for the selection of individual files, groups of files or entire folders. If the appropriate iFilter is found on your system, the application will extract its textual content and save it as a plain text file. Files are named as the source file with a .txt extension and are stored in the same folder.
Application requires Microsoft .NET Famework 2.0
Download: teXtracta 1.0